

引言
在数字时代,数据解析和应用已成为各行各业不可或缺的一部分。小7708论坛作为数据科学和人工智能领域的知名社区,定期发布最新的深度应用数据解析技术。本文将探讨小7708论坛最新发布的SE版23.777中的关键内容和特点,为读者提供一个全面的技术概览。
SE版23.777概述
SE版23.777是小7708论坛最新推出的数据解析工具,它集成了最新的机器学习算法和大数据处理技术。该版本旨在帮助用户更高效地从海量数据中提取有价值的信息,支持复杂的数据分析任务,并提供直观的可视化界面。
核心特性
SE版23.777的核心特性包括:
- 高级数据预处理:包括数据清洗、异常值检测和特征工程等功能。
- 多模型集成:支持多种机器学习模型,如随机森林、梯度提升树和神经网络等。
- 自动化特征选择:通过智能算法自动选择最有助于模型预测的特征。
- 实时数据分析:能够处理实时数据流,支持快速决策和响应。
- 可视化工具:提供丰富的图表和仪表板,帮助用户直观理解数据。
数据预处理的重要性
在SE版23.777中,数据预处理被赋予了极高的优先级。这是因为,无论模型多么先进,如果输入数据的质量不高,最终的分析结果也会受到影响。
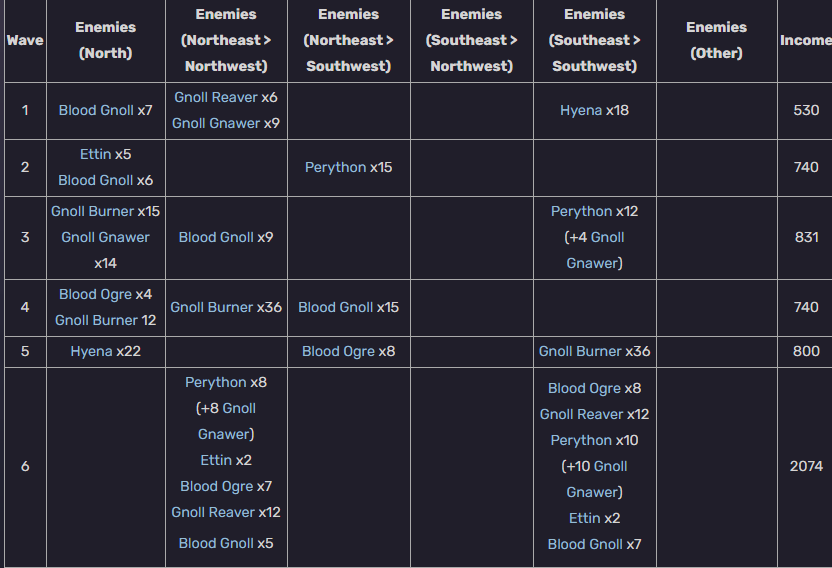
数据预处理包括以下几个步骤:
- 数据清洗:去除重复记录、处理缺失值和纠正错误。
- 异常值检测:识别并处理异常值,以防止它们对模型造成不良影响。
- 特征工程:创建新的特征或转换现有特征,以提高模型的性能。
多模型集成的优势
SE版23.777的一大亮点是其多模型集成能力。这种集成方法可以结合不同模型的优点,提高预测的准确性和鲁棒性。
集成学习是一种强大的技术,它通过组合多个学习器来提高预测性能。SE版23.777支持以下集成方法:
- Bagging:通过创建多个模型的副本并在不同的数据子集上训练它们来减少方差。
- Boosting:通过顺序训练模型并在每一步纠正前一个模型的错误来减少偏差。
- Stacking:将多个模型的预测作为新特征输入到另一个模型中,以提高整体性能。
自动化特征选择的创新
自动化特征选择是SE版23.777中的一个创新点。它通过评估特征与目标变量之间的关系来选择最重要的特征,从而简化模型并提高性能。

这一功能的重要性在于:
- 减少维度:通过去除不相关或冗余的特征来降低数据的维度。
- 提高效率:减少模型训练和预测所需的计算资源。
- 增强模型的可解释性:通过关注最重要的特征,更容易理解模型的决策过程。
实时数据分析的应用
SE版23.777的实时数据分析功能使其在金融、医疗和物联网等领域具有广泛的应用前景。
实时数据分析的关键优势包括:
- 快速响应:能够即时处理和分析数据,为决策提供支持。
- 动态监控:持续监控数据流,及时发现异常或趋势变化。
- 数据驱动的决策:基于最新数据做出更加精准的业务决策。
可视化工具的重要性
SE版23.777提供了一套强大的可视化工具,帮助用户直观地理解复杂的数据和分析结果。

可视化工具的主要功能包括:
- 图表生成:支持生成各种图表,如条形图、折线图和散点图等。
- 交互式仪表板:允许用户与数据进行交互,探索不同变量之间的关系。
- 数据故事讲述:通过可视化手段讲述数据背后的故事,增强






 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...